Redis(Remote Dictionary Server)是一個開源、高性能、基于內存的鍵值對存儲系統,常被用作數據庫、緩存和消息中間件。其設計核心在于提供極快的讀寫速度,這得益于其精心設計的數據結構和獨特的單線程模型。本文將重點探討Redis三種最常用的數據結構及其在單線程模型下如何協同工作,提供高效的數據處理服務。
Redis三大常用數據結構
1. String(字符串)
String是Redis最基本的數據類型,一個鍵對應一個值。它不僅是簡單的字符串,還可以是數字(整數或浮點數)。其常用命令包括SET、GET、INCR(自增)、DECR(自減)等。String類型的應用場景極為廣泛,例如:
- 緩存:存儲會話信息、網頁內容等。
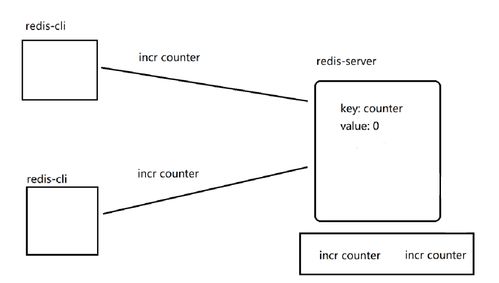
- 計數器:利用
INCR命令實現文章閱讀量、用戶點贊數等。
- 分布式鎖:通過
SETNX(SET if Not eXists)命令實現簡單的分布式鎖機制。
2. Hash(哈希表)
Hash是一個鍵值對集合,特別適合存儲對象。與String一次性存儲整個對象JSON字符串不同,Hash可以將對象的每個字段存儲為獨立的鍵值對,從而支持單獨讀寫某個字段,更加高效。常用命令有HSET、HGET、HGETALL等。典型應用場景包括:
- 用戶信息存儲:將用戶ID作為鍵,用戶的姓名、年齡、郵箱等作為字段存儲,便于部分更新。
- 商品信息緩存:存儲商品的多個屬性。
3. Sorted Set(有序集合)
Sorted Set在Set(無序集合)的基礎上,為每個元素關聯了一個分數(score),元素按分數從小到大排序。分數可以重復,但元素(成員)必須唯一。常用命令有ZADD、ZRANGE(按排名范圍獲取)、ZRANGEBYSCORE(按分數范圍獲取)等。它是實現排行榜功能的理想選擇:
- 實時排行榜:如游戲玩家積分榜、熱搜榜。用戶分數更新后,排序會自動調整。
- 帶權重的隊列:分數可以作為優先級。
單線程模型與高效數據處理
Redis處理網絡請求和數據操作的核心模塊采用的是單線程模型。這意味著在任意時刻,主線程只處理一個命令。這聽起來似乎會成為性能瓶頸,但Redis卻能實現極高的吞吐量,原因如下:
- 純內存操作:絕大部分操作直接在內存中進行,速度極快。
- 非阻塞I/O與多路復用:Redis使用I/O多路復用技術(如Linux的epoll),使得單個線程可以高效地監聽和管理成千上萬的客戶端連接套接字。當某個套接字有命令到達時,線程才進行處理,避免了為每個連接創建線程的開銷和上下文切換的消耗。
- 避免鎖競爭:單線程天然避免了多線程環境中復雜的鎖競爭問題,簡化了實現,提升了整體性能的穩定性和可預測性。
- 高效的數據結構:如上所述,Redis內置了多種經過高度優化的數據結構,其操作的時間復雜度很多都是O(1)或O(log N),執行速度極快。
數據處理服務的協同
在單線程模型下,三種常用數據結構各司其職,共同支撐起Redis作為數據處理服務的角色:
- String 提供最快速、最簡單的鍵值存取,是緩存和計數的基石。
- Hash 提供了對結構化數據的精細化管理,平衡了存儲效率與訪問靈活性。
- Sorted Set 提供了基于分數的有序訪問能力,滿足了排序和范圍查詢的高級需求。
當客戶端發送一個命令(如HGET user:1001 name)時,I/O多路復用器將請求交付給單線程的工作引擎。該引擎解析命令,在內存中找到對應的Hash數據結構,執行查找操作,并將結果通過套接字寫回客戶端。整個過程快速且線性,避免了并發沖突。
值得注意的是,Redis的“單線程”主要指其命令處理核心。一些持久化(如RDB快照生成)、異步刪除等操作是由額外的后臺線程執行的,以避免阻塞主線程。
###
Redis通過將復雜的數據結構(如String、Hash、Sorted Set)與簡潔高效的單線程事件驅動模型相結合,在內存中提供了一個極其快速且功能豐富的數據處理服務。理解這些核心數據結構的特性及其適用的場景,是高效使用Redis的關鍵。而單線程模型則是Redis實現高并發、低延遲能力的架構精髓,使其在緩存、排行榜、會話存儲等眾多場景中成為首選解決方案。